![]()
State configuration
State configuration is the second panel of module Transition analysis.
Access the panel content by pressing
 .
The panel closes automatically after other panels open or after pressing
.
The panel closes automatically after other panels open or after pressing
 .
.
Use this panel to determine the optimum number of transition clusters and associated cross-sample variability.
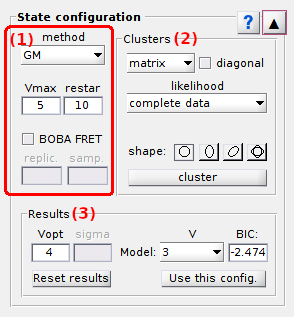
Panel components
Method settings
Use this interface to define a method to cluster transitions.
TDP clustering consists in partitioning the state transitions into groups. Clustering can be done in an iterative fashion to search for the optimum cluster configuration, or in a non-iterative fashion by simply imposing a starting configuration.
The clustering method is chosen in list (a) which includes:
k-meaniterative clustering, with the maximum number of process iteration set in (c)GM(Gaussian mixture) iterative clustering, with the maximum number of mixture initialization set in (c)simplenon-iterative clustering
In all cases, the algorithms look for a number of clusters K that depends on the cluster configuration chosen in Clusters and on the complexity V set in (b), such as:
| configuration | K |
|---|---|
matrix incl. diagonal clusters |
V2 |
matrix excl. diagonal clusters |
V(V - 1) |
symmetrical |
2V |
free |
V |
Once the clusters are identified, states are deduced from the x- and y- coordinates of their centers.
To estimate the cross-sample variability of state configurations, transition clustering can be combined with TDP bootstrapping by activating the option in (d). In that case, the number of replicates used to build a bootstrap TDP sample must be set in (e) and the number of bootstrap samples in (f). By default, the number of replicates is set to the number of molecules in the project.
k-mean clustering
This algorithm uses a starting guess for initial cluster positions and assigns each transition to the nearest cluster center providing a minimum distance to the center, which is defined by the cluster dimensions. Cluster centers are then recalculated by averaging the transitions they are assigned.
Centers are iteratively calculated until the maximum number of iterations set in (c) is reached, or when calculations converged to a stable cluster configuration.
The starting guess for cluster positions and dimensions is defined in Clusters for k-mean or simple clustering.
GM clustering
The GM clustering algorithm has the particularity to infer cluster configurations of different complexities, and then, to determine the most sufficient complexity to describe the data. The method is adapted from the smFRET literature 1.
With GM clustering, a transition cluster is modelled with a 2D-Gaussian. Therefore, the TDP is modelled with a mixture of 2D-Gaussian and each data point has a specific probability to belong to a cluster.
Gaussian mixtures with increasing complexities, up to a maximum complexity set in (b), are fit to the TDP with an expectation-maximization (E-M) algorithm that maximizes the likelihood. For each model complexity, the risk of converging to local maxima is minimized by repeating the fit with random model initializations. The number of model initialization is set in (c).
The most sufficient state configuration is then determined using the Bayesian information criterion (BIC).
The BIC is similar to a penalized likelihood and is expressed such as:
![BIC\left (V \right ) = p\left (V \right ) \times \log ( M_{\textup{total}} ) - 2 \times \log \left [ likelihood\left (V \right ) \right ]](../../assets/images/equations/HA-eq-bic.gif)
with p(V) the number of parameters necessary to describe the mixture, with V the model complexity set in Method settings, and Mtotal the total number of counts in the TDP.
The number of parameters necessary to describe the model includes the number of Gaussian means, pmeans, the number of parameters to describe Gaussian covariances, pwidths and Gaussian relative weights, pweights, and is calculated such as:
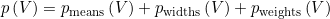
The number of parameters necessary to describe the means of the K 2D-Gaussians depend on the cluster constraint set in Clusters and the complexity V:
| configuration | pmeans |
|---|---|
matrix incl. diagonal clusters |
V |
matrix excl. diagonal clusters |
V |
symmetrical |
2V |
free |
2V |
The number of parameters necessary to describe the weights of K 2D-Gaussians is calculated as: pweights = K - 1
The number of parameters necessary to describe the covariances of K 2D-Gaussians depends on the Gaussian shape:
The Gaussian shape and likelihood calculations used in GM clustering are set in Clusters for GM clustering.
Simple clustering
This algorithm uses user-defined cluster positions and dimensions, and assign transitions to the cluster in which they are contained. When a transition is contained in two different clusters, it is arbitrary assigned to the cluster with the greatest index.
Cluster positions and dimensions are defined in Clusters for k-mean or simple clustering.
References
- S.A. McKinney, C. Joo, and T. Ha, Analysis of Single-Molecule FRET Trajectories Using Hidden Markov Modeling, Biophys. J. 2006, DOI: 10.1529/biophysj.106.082487
Clusters
Use this panel to define the cluster configuration.
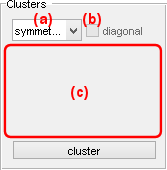
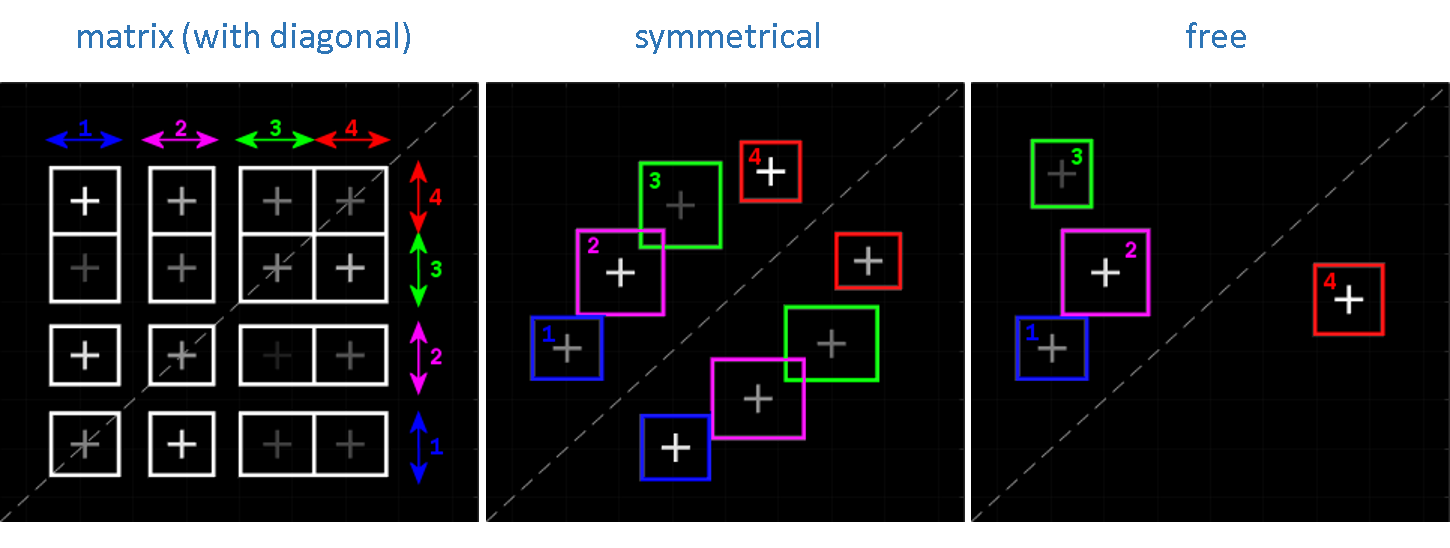
Cluster centers are constrained according to one of the three types of configuration listed in (a):
| constraint | description |
|---|---|
matrix |
V-byV cluster matrix defined by V states |
symmetrical |
V clusters having their symmetrical projection on the opposite side of the TDP diagonal |
free |
V clusters free of constraint |
with V being defined in Method settings.
When using the matrix configuration, the
V clusters on the TDP diagonal are used to group together low-amplitude state transitions that are usually artefacts rising from noise discretization.
To remove diagonal clusters from the matrix configuration, deactivate the option in (b).
The different cluster configurations for a complexity V = 4 are shown below:
The interface (c) defines the shape and coordinates of clusters and depends on the clustering method:
Press
 to start clustering transitions.
If the
Method settings include BOBA-FRET, TDP bootstrapping and subsequent clustering will be performed.
to start clustering transitions.
If the
Method settings include BOBA-FRET, TDP bootstrapping and subsequent clustering will be performed.
After completion, the interface Clustering results and the Visualization area are updated.
Clusters for GM clustering
Use this interface to set the cluster shape and likelihood calculations.
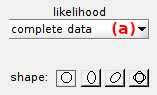
Likelihood calculation is selected in list (a) and can be performed in two ways:
complete-datalikelihood (recommended): associates each transition to one and cluster onlyincomplete-datalikelihood: considers a non-null probability to be associated with each cluster in the configuration (subject to over-estimation of model complexity)
Gaussian clusters can have four different shapes, each being selected by pressing the corresponding button:
| shape | button | description |
|---|---|---|
| isotropic |  |
Gaussian widths are equal in the x- and y- direction |
| straight mutivariate |  |
Gaussian widths can be different in the x- and y- direction and the Gaussian orientation is fixed and defined with 0° inclination |
| diagonal mutivariate |  |
Gaussian widths can be different in the x- and y- direction and the Gaussian orientation is fixed and defined with 45° inclination |
| freely rotating multivariate |  |
Gaussian widths can be different in the x- and y- direction and the Gaussian orientation is free |
Clusters for k-mean or simple clustering
Use this interface to set the cluster shape and center coordinates.
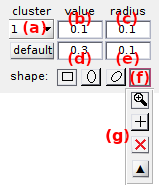
A k-mean or simple cluster is defined by the (x,y) coordinates of its center, its shape and its dimensions.
Clusters can be of three different shapes, each being selected by pressing the corresponding button:
- square by pressing

- straight ellipse by pressing
- diagonal ellipse by pressing
The center and dimensions of the cluster selected in (a) are set:
- by typing the corresponding x- and/or y-value in (b) and/or (d) respectively and the x- and/or y- radius in (c) and/or (e)
- with the mouse selection tool by pressing (f) to open the selection panel (g), and by selecting

- automatically by pressing
 ; in this case, centers are evenly distributed within the TDP limits
; in this case, centers are evenly distributed within the TDP limits
To quit the mouse selection tool, select  in panel (h).
in panel (h).
To reset mouse-selected clusters, select  in panel (h).
in panel (h).
Panel (h) closes after selecting one of the above or by pressing .
Coordinates and radii in the y-direction are not adjustable when using matrix the configuration.
Clustering results
Use this interface to visualize results of a state configuration analysis.
After transition clustering, GM-clustering results are summarized in a bar plot where the BIC is presented in function of the number of components.
The complexity V of the most sufficient model is displayed in (b). When using BOBA-FRET, the bootstrap mean and standard deviation of the most sufficient number of components are respectively displayed in (b) and (c).
Other inferred models can be visualized in the Visualization area by selecting the corresponding number of components in the list (d). The associated BIC value is shown in (e).
Transition clusters of any model can be imported in
State transition rates for dwell time analysis, by pressing
 .
.
Press
 to reset TDP clustering.
to reset TDP clustering.